|
A large fraction of HLA class I ligands are proteasome-generated spliced peptides
Juliane Liepe, Fabio Marino, John Sidney, Anita Jeko, Daniel E. Bunting, Alessandro Sette, Peter M. Kloetzel, Michael P. H. Stumpf, Albert J. R. Heck, Michele Mishto
Science 21 Oct 2016: Vol. 354, pp. 354-358
为了识别病原体和其它致病源,细胞表面存在着通过免疫系统靶向的蛋白质抗原表位片段。这些表位通过蛋白酶体的作用产生,并存在于人白细胞抗原1类(HLA-1)系统中。 蛋白酶体也可以切割蛋白质并将不同片段粘贴在一起,形成跟原始蛋白质序列不一样的多肽。这个过程称为蛋白酶体催化的肽剪接。而这种过程一般认为是相当罕见的。
在这项研究中,作者开发了一种由二维肽初步分割,随后用杂交肽碎片法(电子转移高能碰撞解离)进行肽鉴定的策略。 数据库搜索采用了经过适当调整的 target-decoy的方法,并用了一个很大的全蛋白质组人类剪接肽数据库。
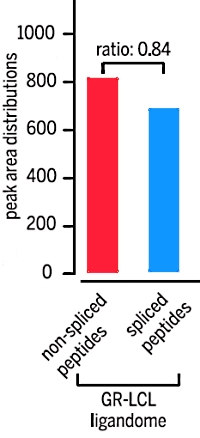
该方法鉴定出了长度为9至12个残基的6592个未剪接的肽和3417个剪接的肽,占鉴定的抗原肽总量的34%。 相反,仅针对标准Swissprot人类蛋白质组数据库搜索这些数据集,错误地将655个抗原肽鉴定为非剪接肽,而没有考虑剪接的肽。 |